目的:
时间和空间维度的分离处理
方法:
时间异常和空间异常,蓝线时间,绿线空间

时间异常:双分支结构,基于CLIP,分别从IMAGE和LABEL两个角度进行分析
视频帧先通过锁定的CLIP IMAGE ENCODER生成帧特征
运动先验感知的空间注意力,将视频帧切分为patch,每个patch通过CLIP获取块特征,并采用空间注意力机制,Xpatch的size是T,H,W,D
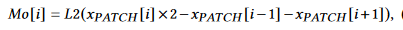
其中Mo是每一帧的差异图,通过计算当前帧和相邻帧的L2范数得到,size是T,H,W,对于每一帧则是H,W
在Mo中选出top -k,作为每一帧运动幅度最大的k个空间特征Xmo,size是T,K,D,用Mo的值指导加权合成
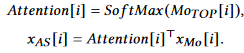
Xas的维度是T,D,把他和视频帧特征进行元素加
这些特征包含了瞬间的空间特征,但是缺乏了全局时间上下文,设计了一个多层Transformer的结构
采用相对距离来计算帧之间的相似度,通过SOFTMAX加权融合,最后通过FFN

这里出来后的特征考虑了时间的上下文相关性,SIZE是T,D
后续类似,双分支提示学习,C分支提供帧级别置信度分类,A分支提供对齐
注意此处这俩分支无联动
C分支提供帧级别的是否异常分类,即对于T,D输入,输出是T,1,最后通过top-k的平均值作为此视频是否异常的概率,并于GT做二元交叉熵损失
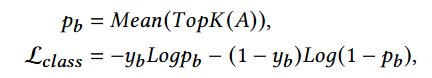
A分支提供文本和图像的相似性矩阵
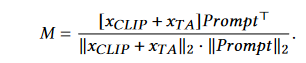
M的size是T, (1+C),视频特征维度是T, D Prompt维度是(1+C),D
选择每一行的top-k值作为这一类与整个视频的相似度,组成最后视频级的相似度向量S,维度是1+C

最后是对比损失,优化prompt,相似类别嵌入靠近

空间异常:
空间异常定位,先对异常帧做滑动窗口生成patch,输入到CLIP中获取token嵌入
文本查询生成,分为正常和异常,最后将文本通过clip的text encoder
正常的描述比较困难,因此采用描述背景文本,选择了常见的室内室外物品
“a picture of sky, a picture of ground, a picture of road, a picture of grass, a picture of building, a picture of wall, a picture of tree, a picture of floor tile, a picture of desk, a picture of cabinet, a picture of chair, a picture of door, a picture of blank”。
异常描述的生成: 对于异常描述,除了原始的异常类别描述外,我们还使用 LLMs 和模板 “Provide phrases similar to [abnormal category]” 来获取增强描述。例如,[abnormal category] 可以设置为 “people knockout someone”(打斗类),”people lying on the ground”(车祸类),”someone ignite fire”(纵火类),”people shooting someone”(枪击类)。这些增强提示与原始文本类别一同作为最终的异常提示,用于空间异常定位。
将空间补丁特征xp和文本查询特征qt,采用相似度来检索
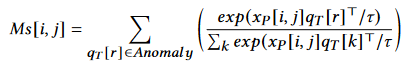
总结:
时间上设计特征差异性来强化局部特征,全局上下文采用相对距离作为相似度做注意力
空间上采用LLM设计prompt计算相似度热图