目的:
预训练模型的微调伴随着模型参数的增大带来了更大的压力,本文提出了lora,冻结了预训练的权重,通过在transformer架构的每一层注入可训练的秩分解矩阵,减少下游任务中需要训练的参数数量
方法:
添加一组尺寸更小的参数,将任务优化修改为
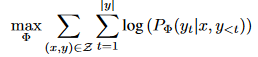
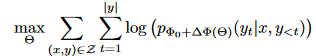
先前的方法:
adapter:
在transformer块中添加多个adapter层,缺点是无法绕开额外计算。大型网络结构依赖硬件并行来保持低延迟,然而adapter必须顺序处理,因此会需要更多时间
prefix tuning:
前缀调优很难优化,在可训练参数中变化不稳定
LoRA:
对神经网络来说,其中的权重矩阵通常是满秩的,但是针对特定任务,例如语言模型,只需要比较低的内外维度,也就是随机投影到更小的子空间上时,仍然可以高效的学习
对于预训练好的参数W,采用低秩分解来约束更新
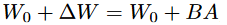
其中W_0 \in R^{d \times k},B \in R^{d \times r}, A \in R^{r \times k}, r \ll min(d,k)
其中W0是冻结的,不接受梯度更新,而AB包含可训练的参数,他们都接受相同的输入相乘,例如
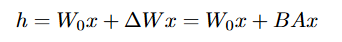
对于AB,采用高斯随机初始化A,并且将B置0,采用\frac{\alpha}{r}来缩放BAx,其中α类似于学习率
总结:
1.类似resnet和encoder的做法,将大模型针对特定任务的微调转换给基于大模型的参数添加参数偏置,而对于特定任务,其并不需要完整参数空间的满秩,只需要低秩空间就可以满足需求,因此可以将参数偏置拆解为两个低秩矩阵,降低了训练成本