Video Anomaly Detection in 10 Years: A Survey and Outlook
问题定义:
将原始数据转化为可解释的特征表示,并利用强大的特征提取器来捕捉视频中的时空特征
将视频定义为一系列帧组成的视频,将每一帧中提取的特征通过模型获得异常得分,视频的得分为所有异常帧得分之和,超过阈值则为异常
方法分类:
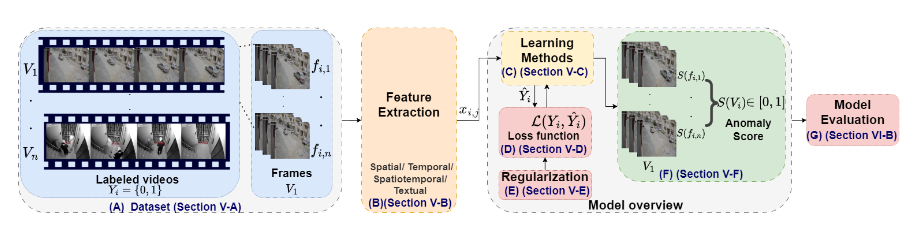
1.学习和监督方案
- 有监督:给定标注数据
- 自监督:通过自我生成标签来训练,依赖数据本身的结构
- 弱监督:例如多实例学习MIL,弱标注数据进行学习
- 无监督:分为单类分类(仅采用正常数据训练),重建方法(学习数据的重建方式,AE),未来帧预测(预测未来帧是否符合正常模式)
2.特征提取维度
采用深度学习的方式提取特征较为常见
- CNN,AE,GANS,LSTM,ViT,VLM等
类型有:
- 空间特征,时间特征,时空特征和文本特征
数据集:
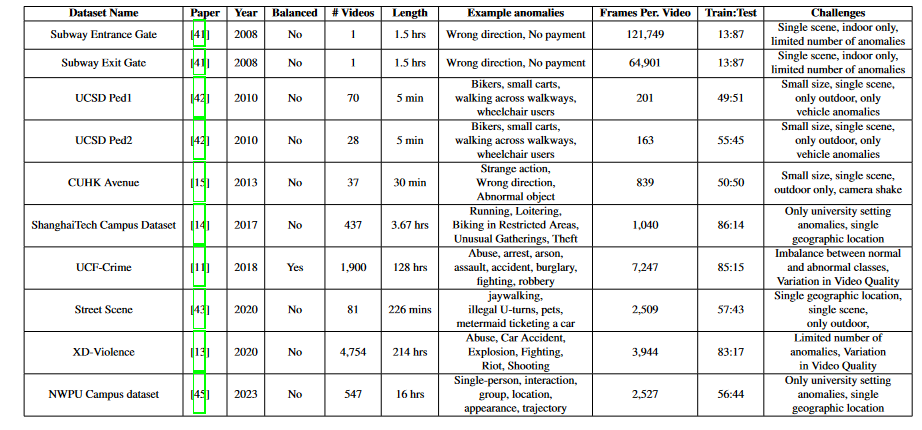
1) Subway 数据集
Subway 数据集[41]包括两个视频,分别通过 CCTV 摄像头拍摄,捕捉地铁车站不同视角的场景。第一个视频聚焦于“入口门”区域,通常有行人通过旋转门进入站台,并且背对着摄像头。第二个视频位于“出口门”区域,观察的是乘客上楼的过程,乘客面向摄像头。这两个摄像头提供了车站内不同的视角,对分析和监控具有重要价值。数据集的总时长为 2 小时。该数据集的异常事件包括行走方向错误和徘徊等,主要记录的是室内环境中的异常行为。
2) UCSD Pedestrian 数据集
UCSD 数据集[42]通过一个固定的摄像头,位于高处监控行人走道,捕捉了不同人群密度下的场景,涵盖从稀疏到拥挤的环境。正常视频主要展示行人,而异常事件来源于两种主要的情况:走道内出现非行人实体,以及行人的异常运动模式。常见的异常包括自行车骑行者、滑板者、小推车、在人行道上或草地上走动的人,甚至是坐轮椅的个体。该数据集由两个子集组成,Peds1 和 Peds2,分别捕捉不同的场景,Peds1 展示了人群朝向或远离摄像头走动的场景,Peds2 则主要捕捉人群与摄像头平行运动的场景。数据集包括多个视频片段,每个片段包含大约 200 帧。为评估算法的异常定位能力,部分视频片段配有手动生成的像素级二进制标注。UCSD 数据集的两个子集公开提供:UCSD数据集官网。
3) Street Scene 数据集
Street Scene 数据集由 Ramachandra 等人提出[43],包括 46 个训练视频和 35 个测试视频(分辨率为 1280×720)。这些视频通过 USB 摄像头拍摄,覆盖一个两车道街道,并包括自行车道和人行道。该数据集呈现了多种挑战,包括汽车驾驶、转弯、停车;行人走路、慢跑、推婴儿车;自行车骑行等活动。此外,视频中还有不断变化的阴影、移动的背景(如飘动的旗帜、风中的树木),以及大车遮挡等复杂情况。数据集包括 56,847 帧用于训练,146,410 帧用于测试,采样率为每秒 15 帧。异常事件包括非法穿越马路、非法掉头、宠物走路、罚单等。这些多样化的异常事件为视频异常检测提供了一个全面而具有挑战性的研究资源。数据集的公开地址:Street Scene数据集官网。
4) UCF-Crime 数据集
UCF-Crime 数据集[11]是一个大规模的多场景数据集,包含 13 种涉及公共安全的异常行为。数据集涵盖包括虐待、逮捕、纵火、袭击、交通事故、入室盗窃、爆炸、打斗、抢劫、射击、偷窃、商店盗窃和破坏等异常事件。数据集共包含 950 个未剪辑的现实世界监控视频,涵盖明显的异常行为,配有与之相对的 950 个正常视频,总计 1900 个视频。数据集经过严格的筛选和标注,确保质量和完整性,提供了时间级标注,标注视频中异常事件的发生时间。数据集分为训练集(800 个正常视频,810 个异常视频)和测试集(150 个正常视频,140 个异常视频)。UCF-Crime 数据集是评估多种异常检测算法的理想资源。数据集公开地址:UCF-Crime数据集官网。
5) CUHK Avenue 数据集
CUHK Avenue 数据集[15]由香港中文大学(CUHK)研究人员提出,是广泛应用的视频异常检测资源。该数据集设置在CUHK校园大道,涵盖了城市环境和公共街道上常见的异常事件。数据集包括多种光照条件、天气变化和人类活动,呈现出VAD模型面临的巨大挑战。常见的异常行为包括打斗、突然跑步、异常聚集以及错误的运动方向等。此外,数据集还面临一些挑战,如摄像机抖动、训练集缺乏正常行为的样本以及训练数据中的离群点。数据集包含 30,652 帧视频,15,328 帧用于训练,15,324 帧用于测试。数据集的公开地址:CUHK Avenue数据集官网。
6) ShanghaiTech 数据集
ShanghaiTech 数据集[14]是异常检测领域的一个重要贡献,涵盖了 13 个场景,具备复杂的光照条件和多种拍摄角度。数据集包含超过 270,000 帧的训练数据和 130 个异常事件,异常事件在像素级别进行了详细标注。数据集包含 330 个训练视频和 107 个测试视频,分辨率为 856×480,帧率为 24 fps。这个数据集为异常检测方法提供了一个坚实的基础,并在现实场景中具有高度的应用价值。数据集的公开地址:ShanghaiTech数据集官网。
7) XD-Violence 数据集
XD-Violence 数据集[13]是一个大型的多场景数据集,包含 217 小时的 4754 个未剪辑视频。数据集聚焦于弱监督的暴力行为检测,仅提供视频级别的标签。它涵盖了六类暴力事件:虐待、车祸、爆炸、打斗、暴动和枪击。该数据集为训练数据驱动的暴力检测系统提供了一个重要的资源,适用于大规模视频数据集的训练。数据集的公开地址:XD-Violence数据集官网。
8) NWPU Campus 数据集
NWPU Campus 数据集[45]是一个新近发布的异常检测数据集,旨在支持视频异常预测。该数据集包含来自校园内 43 个户外场所的视频,捕捉了行人和车辆的行为。数据集涉及单人、交互、群体、场景依赖、位置、外观和轨迹等多种异常。它是首个为视频异常预测设计的数据集,具有较大的数据量和丰富的场景。数据集公开地址:NWPU Campus数据集官网。
9) 数据集讨论
现有文献中呈现了多种多样的公共数据集,涵盖了广泛的正常和异常场景。这些数据集从单一场景的数据集(如 UCSD Pedestrian 数据集)到多场景数据集(如 UCF-Crime 和 XD-Violence 数据集)不等,涵盖的异常类型也各不相同。例如,CUHK Avenue 数据集仅集中于大学校园场景,而 UCF-Crime 数据集则涵盖了多个实际场景中的不同异常事件。这些数据集的挑战包括:
- 环境多样性不足:许多公开数据集仅涉及特定场景,限制了训练模型的泛化能力。
- 异常事件数量有限:一些数据集的异常类型较少,这限制了模型的学习范围。
- 类别不平衡:许多数据集的正常类和异常类的样本数量不平衡,导致模型偏向正常类。
特征学习:
不同类型的特征:
- 空间特征,在机器学习领域曾经设计过,例如高斯混合模型手动构造特征等,目前被深度学习替代
- 时间特征,随时间变化的元素,例如运动,速度变化,帧与帧之间的环境变化等
- 时空特征,单独以来时间特征和空间特征可能会限制模型,比如时间特征无法定位发生的位置,空间特征可能忽略时机
- 文本特征,字幕和标签可以显著提升系统理解和识别异常的能力
特征提取器:
- 2D CNN:对视频帧图片进行特征提取
- 3D CNN:加入时间分析,有效评估时空特征
-
AE:无监督的情况下学习数据的关键特征
- GANs:类似的 学习数据的分布
- 顺序深度学习:LSTM,VIT处理顺序数据
- VLM:视觉语言模型
监督方法:
有监督:
利用每一帧都已经标注正常或者异常的数据集上进行开发,缺点是标注数据集带来的资源消耗较大
[62]研究
该研究提出了一种使用时空卷积神经网络(CNN)检测和定位拥挤场景中的异常的方法。这种方法能够同时处理来自视频序列的空间和时间数据,捕捉到外观和运动信息。特别针对拥挤环境,该方法通过聚焦于移动的像素来高效识别异常,增强了准确性和鲁棒性。
[53]研究
针对标注异常样本稀缺的问题,该研究通过使用条件生成对抗网络(cGAN)生成额外的训练数据,从而解决类不平衡问题。该方法使用标注数据进行模型训练,并提出了一种新的监督异常检测器——集成主动学习生成对抗网络(EAL-GAN)。这种网络的独特之处在于其架构是一个生成器与多个判别器对抗,通过集成学习损失函数和主动学习算法,旨在缓解类不平衡问题并降低标注现实世界数据的成本。
自监督:
自监督学习方法通过使用未明确标注为异常的数据来训练模型。与传统监督学习不同,自监督学习不依赖于标注的异常事件,而是通过解决“代理任务”(proxy tasks)从数据本身生成监督信号
[9]研究
研究人员提出了一种基于自监督和多任务学习的方法,聚焦于对象级别的异常检测。具体来说,该方法使用3D卷积神经网络(CNN)来解决几个代理任务,任务本身不需要标注的异常数据。任务包括:
- 确定物体的运动方向(时间箭头),即理解物体在视频中的移动方向。
- 通过对比连续帧和间隔帧,检测物体运动的不规律性。
- 基于前后帧重建物体外观,帮助模型理解物体的外观变化。
通过学习这些代理任务,模型能够理解什么是正常的物体行为,从而在遇到偏离正常行为时检测到异常。即使没有明确的标签数据,这种方法仍然能有效识别视频中的异常事件。
[63]研究
在后续的工作中,研究人员进一步优化了自监督方法,加入了更先进的物体检测技术,如YOLOv5、光流(optical flow)和背景减除(background subtraction)。这些改进提高了对快速运动物体和不属于预定义类别的物体的检测能力。此外,研究人员还引入了变换器(transformer)模块,探索了2D和3D卷积视觉变换器(CvT),以更好地捕捉复杂的时空依赖关系。这些更新增强了框架的鲁棒性,显著提高了在视频序列中识别异常事件的准确性和适应性。
弱监督:
弱监督学习方法与传统的监督学习方法不同,它不依赖于精确的帧级标注,而是通过对视频中的短片段进行标注来训练模型,这些标注仅表明片段中是否存在异常。这种方法的优势在于能够在标注困难且耗时的情况下进行视频异常检测。然而,这种方法也面临着一些挑战,尤其是在标注的精确度和一致性方面。
弱监督学习的工作原理
- 标注方式:与传统监督学习方法需要每一帧的精确标签不同,弱监督学习通过标注视频中的“片段”来进行训练。这些片段可能包括正常或异常事件的部分,但这些标注并不提供关于异常具体位置的详细信息。片段级的标签为训练模型提供了一个弱监督信号,但由于这种模糊性,可能导致模型学习到的特征不如传统监督方法精确。
- 多实例学习 (MIL):最早由Sultani等人提出,采用了多实例学习模型来解决弱监督学习中的异常检测问题。在这种方法中,视频被视为负袋(normal)和正袋(anomalous),视频片段作为实例进行处理。特征提取器首先提取时空特征,然后通过全连接网络来输出最终的异常分数。尽管该方法能够有效地处理弱标注数据,但由于弱标注可能引入噪声,模型可能会学习到不准确的正常和异常行为的表示。
图卷积网络(GCN):例如,[28]提出了一种创新的弱监督异常检测方法(WSVAD),将其视为一个有噪声标签的监督学习任务,脱离了传统的MIL框架。通过利用图卷积网络(GCN),该方法能够有效地清理噪声标签,从而提高异常检测的训练效果和分类器的可靠性。
二值化嵌入(BE-WSVAD):在[64]的工作中,引入了二值化嵌入(BE-WSVAD)方法,嵌入二值化过程以改进基于GCN的异常检测模块,从而提高异常检测的准确性。
时间卷积网络(TCN)与内袋损失(IBL):另一个创新性的方法[27]结合了传统的MIL框架与时间卷积网络(TCN)和独特的内袋损失(IBL)。IBL专注于分析每个视频片段内异常分数的变化,推动正袋(包含异常的片段)之间的分数差距增大,而负袋(正常片段)之间的差距较小。TCN则有效捕捉视频中的时间动态,弥补了标准MIL方法在时序处理方面的不足。
自推理与伪标签生成:[29]和[65]提出了一种自推理方法,通过对时空视频特征进行二值化聚类来缓解异常视频中的标签噪声。该方法通过聚类生成伪标签,并通过聚类距离损失来进一步提升检测性能。
关系感知与自注意力机制:为了更好地捕捉复杂的行为和相互作用,[31]提出了一种关系感知特征提取器,该方法结合了自注意力和条件随机场(CRF)。自注意力用于捕捉短程特征相关性,而CRF则用于学习特征之间的依赖关系,帮助更全面地分析视频中的复杂运动和交互。
鲁棒时间特征幅度学习(RTFM):针对视频中稀有异常片段的识别困难,[32]提出了鲁棒时间特征幅度学习(RTFM)方法。该方法通过时间特征幅度学习增强MIL方法的鲁棒性,特别是在面对正常事件主导的场景时,对于细微异常的检测能力得到了显著提高。
多实例自训练框架(MIST):[52]提出了一种新的弱监督自训练框架,MIST,专门用于视频异常检测。MIST通过引入伪标签生成器和稀疏连续采样策略来获取更准确的片段级伪标签,并使用自引导注意力增强特征编码器来关注帧内的异常区域。
弱监督时序关系学习(WSTR):[66]提出了一个新的弱监督时序关系学习框架(WSTR),该框架采用I3D提取特征,结合片段级分类器和top-k视频分类来进行弱监督学习。该方法首次在弱监督异常检测任务中应用了变换器技术。
基于CLIP的弱监督方法:[26]提出了一个名为CLIPTSA的弱监督方法,利用CLIP模型的视觉语言(ViT)特征进行异常检测。CLIPTSA结合了时序自注意力(TSA)机制,有效建模了长短时依赖关系,显著提升了异常检测的性能。
文本提示与正常性引导(TPWNG):[61]提出了基于CLIP模型的文本提示与正常性引导方法(TPWNG)。该方法通过利用CLIP模型对视频帧和文本描述进行对齐生成伪标签,并引入正常性视觉提示机制来改进文本视频对齐。通过正常性引导模块生成伪标签,并结合自适应时序学习模块来灵活捕捉视频事件的时序依赖关系,从而提升了异常检测性能。
无监督:
基于重建的视频异常检测方法依赖于“正常事件可以从学习到的表示中有效重建,而异常事件则偏离这些表示,从而更难重建”这一原则。模型通过学习表示或“重建”正常数据,在此基础上,通过检测重建误差来识别异常事件。这些方法尤其适用于标注异常数据稀缺的场景。
常见方法
- 自编码器(Autoencoders):自编码器是一种常用的深度学习方法,它通过学习将输入数据压缩成低维表示,然后尝试从这个低维表示中重建原始数据。在训练过程中,模型学习最小化输入数据与重建输出之间的误差。训练完成后,当模型遇到新数据时,它会基于已经学习到的模式进行重建。如果重建误差很高,则该数据被认为是异常的。
- 卷积神经网络(CNN):CNN也广泛应用于视频异常检测中的重建任务,特别是当输入数据具有强烈的空间特征时。卷积自编码器通过卷积层来处理视频帧,以提取空间特征并执行重建。
基于自编码器的异常检测:例如,[16]提出了一种使用重建模型评估视频序列中帧的常规性的方法。该方法使用了两个自编码器,一个包含卷积层,另一个不包含卷积层。模型分别处理了两种不同类型的输入:一是手工设计的特征(如HOG和HOF,增强了基于轨迹的特征);二是沿时间轴对齐的10个连续帧的组合。重建这些帧的误差作为常规性分数的指标,帮助检测异常
损失设计:
- MIL损失,要求正常视频的异常得分最小,异常视频得分最大
- 二元交叉熵损失,与标签运算
- 在无监督任务中,设计重建损失,要求解码器的数据和原始数据接近,如果误差大说明数据可能是异常的
正则化:
1) 权重衰减正则化(Weight Decay Regularization)
权重衰减是一种常用于神经网络训练中的正则化方法,用来防止过拟合。具体来说,权重衰减通过在训练过程中向损失函数中添加与模型权重大小相关的惩罚项,来减少权重的大小。权重衰减的目标是保持权重较小,这有助于减少模型的复杂性并降低过拟合的可能性。通过惩罚较大的权重,权重衰减确保模型不会过度依赖任何单一特征或特征组合,从而提高模型的泛化能力。
a) L1 正则化
L1 正则化是将模型的权重绝对值大小作为惩罚项添加到损失函数中。L1 正则化的损失函数可以表示为:
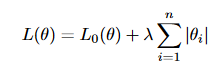
b) L2 正则化
L2 正则化,也称为岭回归(Ridge Regularization),通过在损失函数中添加与权重平方成正比的惩罚项来修改模型的训练过程。L2 正则化的损失函数表示为:
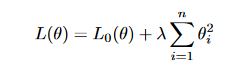
2) 时间和空间约束
时间和空间约束是视频异常检测中常用的正则化项,这些约束在损失函数中加入后,可以确保模型在时空学习方面的稳定性,有助于区分视频中的正常和异常事件[73]。时间约束用于保证事件在时间上的连续性和进展,而空间约束用于增强模型对物体位置和物理位置的理解,以识别视频帧中的异常存在。通过在VAD模型的损失函数中加入这两种约束,模型能更有效地进行异常检测。
a) 时间平滑约束(Temporal Smoothing Constraint)
时间平滑约束是VAD损失函数中的一个重要组成部分,旨在保持预测的异常评分在连续帧之间的稳定性。这个约束的目标是减少相邻帧之间异常评分的剧烈波动,因为我们期望相邻的帧通常会展现相似的异常特征。时间平滑约束通过惩罚连续帧之间异常评分的急剧变化来实现,如下公式所示:
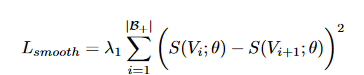
b) 稀疏性约束(Sparsity Constraint)
稀疏性约束是VAD中常用的一种正则化项,它强制要求异常帧在视频帧中占较小的比例。在VAD中,通常假设异常帧的数量比正常帧少,稀疏性约束通过惩罚视频中异常帧的总数来实现,公式如下:
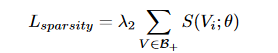
评估指标:
- ROC曲线下面积(AUC)
真正率
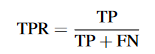
假正率
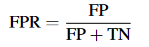
AUC为面积,越靠近1越好,0.5表示随机分类,靠近0表示乱分类