目的:
建模一个三维语言场,使用户能够使用开放性语言与三维世界进行交互。用3DGS中的高斯去编码从CLIP中提取的语言特征
方法:
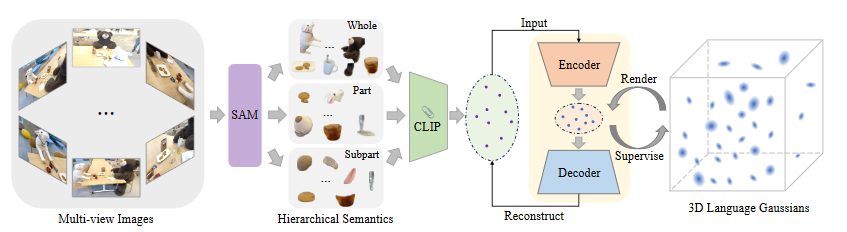
三维语言场的原理和问题:
将输入图像表示为I\in R^{3\times H \times W},采用一组校准后的推向作为输出,用此来训练一个三维语言场\Phi
目前的大多数方法通过CLIP编码器V来提取图像特征,并通过提取的CLIP嵌入来监督三维语言场,利用CLIP提供的良好对齐的文本-图像潜在空间来推动词汇查询
然而,CLIP是图像并不是像素对齐,因此计算V(I_t) \in R^D只能获得图像级别的特征,而不是像素对齐的语言嵌入L_t \in R^{D \times H \times W},其中D是CLIP特征的维度
建模像素对齐的语言特征可能会命令点模糊的问题,因为一个点可能会贡献给多个语义层次的区域
常见做法是对于给定坐标的像素,通过以像素为中心不同绝对物理尺度s的图像不定重获得的,期望在某个尺度s上,补丁可以完全包围对象
可能导致语言场过于平滑,边界不清晰,会采用额外的像素级对齐DINO来监督网络,并且尺度太多降低了速度
利用SAM的层次语义学习:
作为图像分割的基础模型,SAM可以准确地将一个像素与属于同一对象的周围像素分组,从而将图像分割成具有清晰边界的多个对象掩码。此外,SAM通过生成针对点提示的三种不同掩码(即整体、部分和子部分)来解决点模糊问题,代表三种层次语义。在本文中,我们提出利用SAM获取精确的对象掩码,然后用于获取像素对齐的特征。我们还明确建模由SAM定义的语义层次结构,以解决点模糊问题。通过SAM,我们可以捕捉3D场景中对象的语义层次,为每个输入图像提供准确的多尺度分割图。
通过SAM为每张图像生成子部分,部分和整体的掩码图
获取了分割图后,为每个分割区域提取CLIP特征,数学上来说
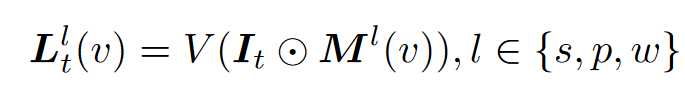
其中M^l(v)表示像素v在语义层次l上所属的掩码区域,通过指定预定义的尺度,消除了在多个绝对尺度上进行密集搜索的需要
3DGS在语言场的运用:
3DGS不再赘述,本文为3DGS设计了三个语言嵌入f^s, f^p, f^w,均来自CLIP特征,捕捉SAM提供的层次语义
类似的,采用3DGS的渲染器
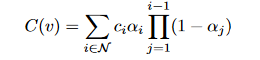
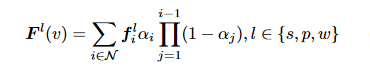
作为一种显示方法,3DGS会创建数百万个3D点来建模一个复杂的3D场景,与球谐系数表示的RGB不同,直接在CLIP空间学习f会增加内存和时间成本,因此设计一个语言自编码器,将CLIP嵌入映射到低维潜在空间
考虑到CLIP已经在足够多的数据集中进行了训练,其现有的D维空间是非常紧凑的,因此我们需要利用场景先验来压缩CLIP特征
具体的,对于每个输入图像,我们可以获得由SAM分割的数百个掩码,这些掩码显著少于CLIP的训练数据量,因此这些分割区域的CLIP特征在潜在空间中是稀疏分布的,允许使用自编码器进一步压缩特征
设计一个Encoder Decoder对,将CLIP映射到低维,再通过一个解码器从压缩中重建原始的CLIP嵌入
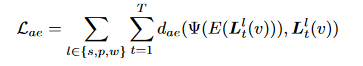
训练完成后,使用所有编码后的潜在特征{H^l_t}作为语言嵌入,因此3DGS会在场景决定的潜在空间中学习
用下列目标来优化3DGS
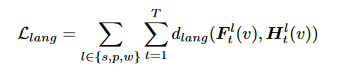
总结:
1.CLIP强调图像的语言嵌入,而SAM强调像素的掩码归属
2.采用SAM作为不同层次的掩码提取,减少了CLIP的语言嵌入点模糊问题
3.采用3dgs作为载体,承载了每个空间中的3d点的语言嵌入
4.设计每个场景决定的编码解码器,用于将语言嵌入映射到更低维度,减少内存开销