目的:
利用对比进行去噪训练,混合查询方法进行锚点初始化
方法:
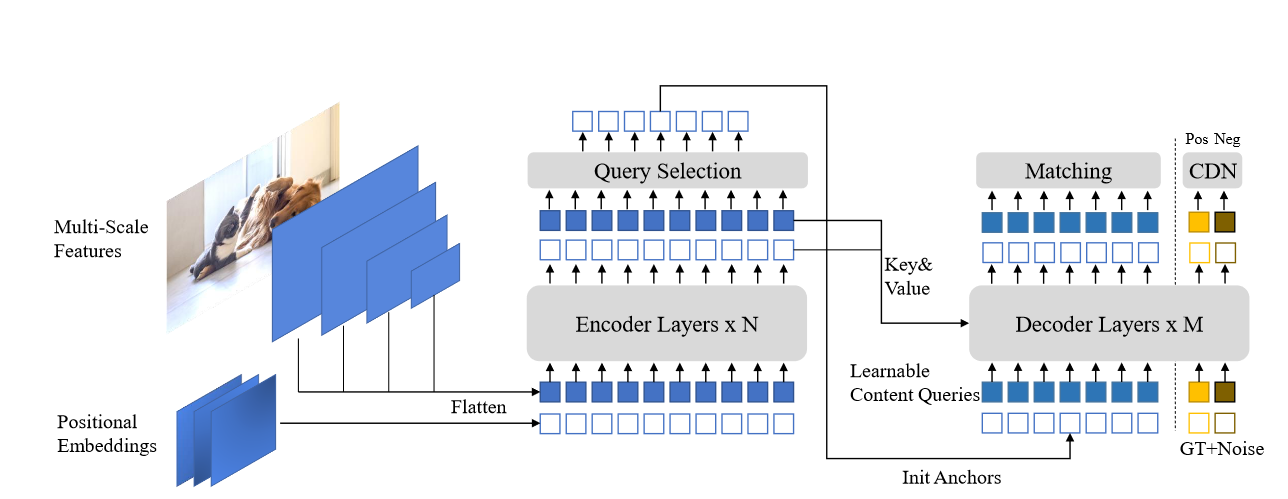
在C-DETR和DAB-DETR中可以知道,DETR的查询可以分为两部分,内容查询和位置查询,内容查询的结果是类别标签,位置查询的结果是框的4D坐标。
DN-DETR通过引入去噪的方式来加快DETR的收敛,将含有噪声的真实标签输入到Transformer解码器中,训练重构真实标签和边框。
Deformable DETR则是为了计算可变形注意力,引入了参考点的概念,使得注意力可以关注参考点周围的一圈关键采样点。
本文将位置查询表示为动态锚点,使用额外的DN损失进行训练
特征:
通过ResNet或者Swin Transformer骨干网络来提取多尺度特征,将特征和位置嵌入输入Transformer编码器,进行特征增强
去噪和对比:
DN在稳定训练和加速收敛方面非常有效,但是缺乏预测没有对象的能力,因此设计了CDN模块用于排除无用的锚点
在DN-DETR中,我们用\lambda来控制噪声规模,在DINO中,有两个超参数\lambda_1,\lambda_2, \lambda_1<\lambda_2,如下图的同心方框
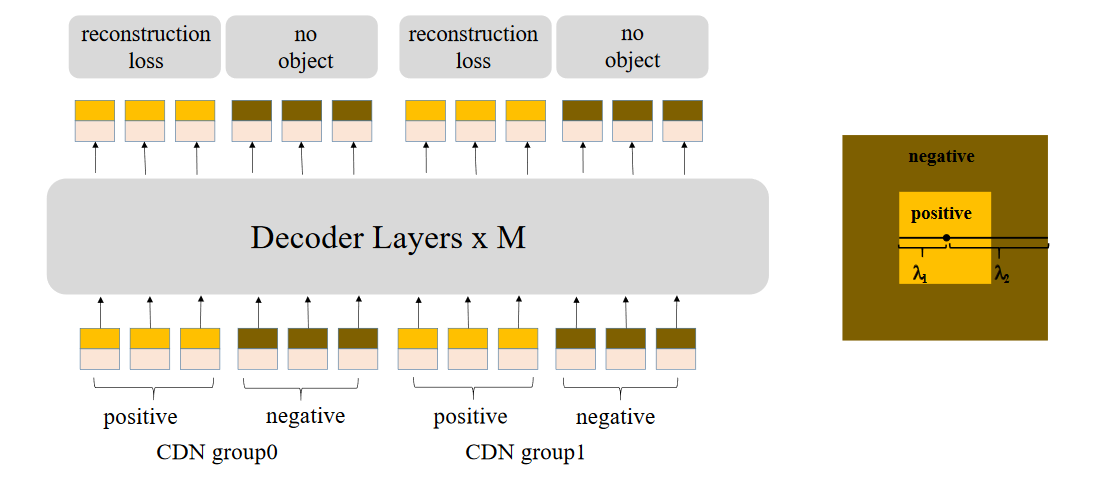
并且构造两种类型的CDN查询,内方框的正查询噪声规模小于\lambda_1,内外方框之间的负噪声查询大于\lambda_1小于\lambda_2,对于有着n个GT框的图像,可以构造2n个CDN查询,我们希望模型对正查询框重建真实方框,对负查询框预测没有对象,如上图的重建损失和无对象
混合查询:
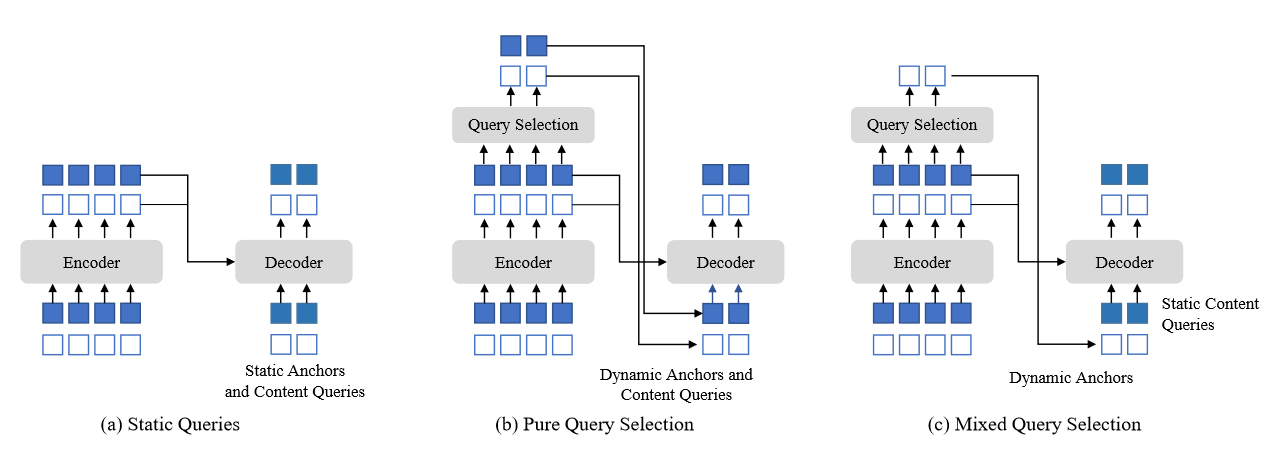
在DERT和DN-DETR中,Transformer解码器的查询是静态嵌入,不包含来自图像的任何编码器特征,直接从训练数据中学习锚点或者位置查询,并且将内容查询设为全零向量
DINO采取了混合查询的策略,从编码器的最后一层选取钱K个特征关联的位置信息初始化锚点框,同时保持静态的内容查询,与Deformable DETR相比,它采用前K个特征增强位置查询和内容查询,然而内容查询的增强可能带来歧义,例如一个特征可能包含多个对象或者对象的一部分
迭代方法:
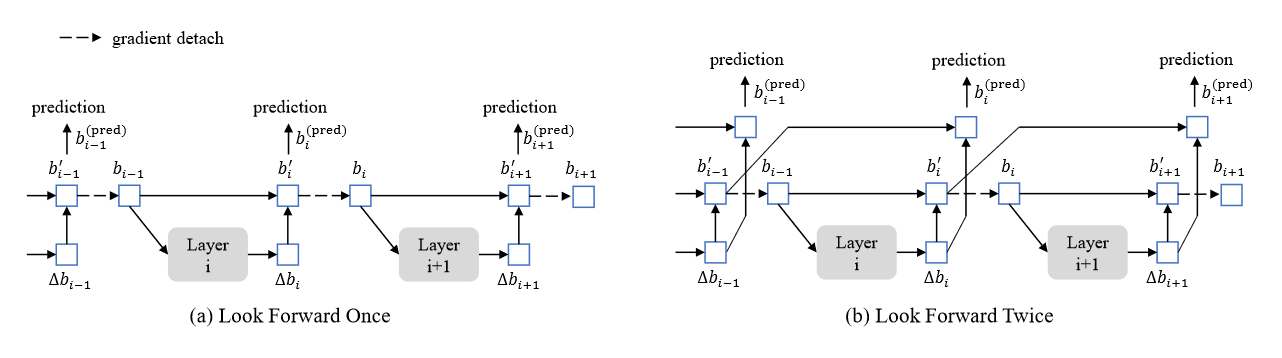
Deformable DETR采用了向前看一次策略,阻止了梯度反向传播来稳定训练,DINO修改为向前看两次
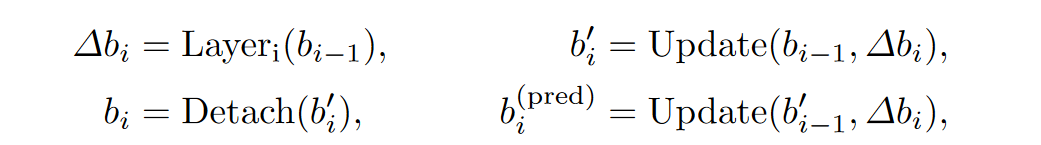
总结:
1.通过对比去噪提高了模型判断无对象的能力
2.混合查询,是的模型可以从图像中学习位置查询的信息,同时保持内容查询的独立性
3.迭代方法优化,可以纠正早期层的框预测