目的:
将目标检测视为直接集合预测
方法:
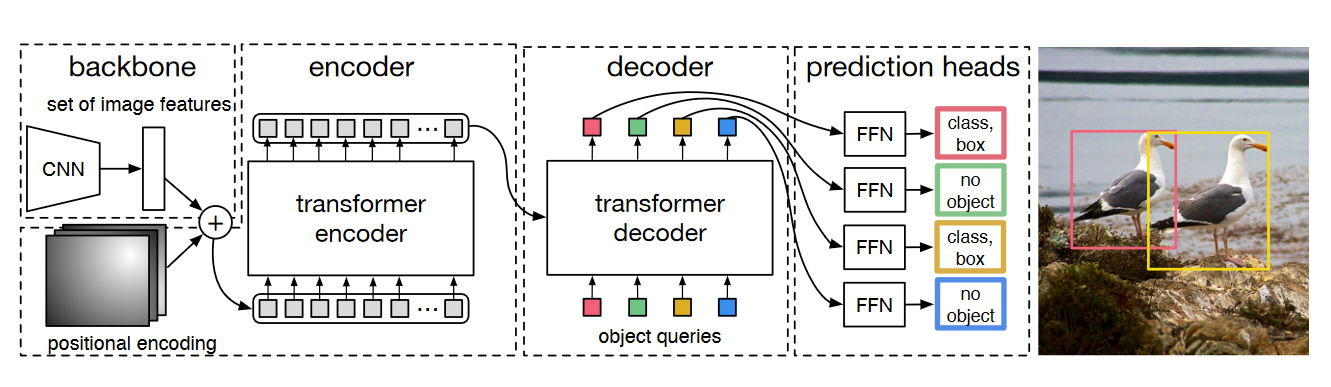
架构:
DERT的主要架构由三个部分组成,CNN特征提取器,Transformer编码解码器,FNN前馈网络作最终预测
CNN:
x \in R^{3\times H_0 \times W_0 } \rightarrow f \in R^{C \times H \times W}
从原始图片生成多通道的具有较低分辨率的激活图f
Transformer:
Encoder:
先通过1 \times 1卷积将高层激活图f减少到低维度d,生成新的激活图z_0 \in R^{d \times H \times W},由于Transformer要处理序列,将其展平为1维d \times HW的特征图
进行多头自注意力和前馈FFN
Decoder:
对于大小为d的N个嵌入,解码器将这N个对象查询转换为输出嵌入,最后将输出嵌入通过前馈的FFN生成类别标签和框坐标信息,最终得到N个结果
FNN:
3层含有relu激活函数和d维度隐藏层的感知机,预测相对于输入图像归一化的框坐标和高度宽度,线性层利用softmax预测类别标签,用一个特殊的标签来表示无对象
损失:
DETR单次推断出固定大小的N个预测,其中N远大于图像中典型的物体数量,寻求一个排列,使得预测的元素排列和真实的标签集合(空白的用无物体填充)匹配代价最低
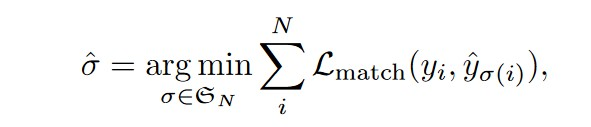
真实标签的每个元素可以看成目标类别c加位置参数b,其中b \in [0,1]^4,分别表示中心坐标和框相对于图像尺寸高度和宽度的比例,此时的匹配代价为

前一项为类别损失,后一项为框误差,对于边界框损失

补充知识:
Multi-head attn:
对于多头注意力,下面做一些简单介绍
多头注意力一般具有M个维度为d的注意力头,其中具体形式如下

X_q是长度为N_q的查询序列,维度为d,X_{KV}是长度为 N_{kv}的键值序列,为了方便,维度也为d,T是映射矩阵,可以看作是Q,K,V三个映射矩阵concate起来,L是映射矩阵,用于将查询序列映射后作残差处理
其中,多头自注意力是多头注意力的特殊情况,其X_q = X_{KV}

多头注意力可以理解为将M个单独的注意力头拼接起来,再通过L进行投影

此处使用了残差连接,Dropout和层归一化
Single-head attn:
多头注意力可以看作多个单头注意力的叠加,下面简单介绍下单头注意力
一个具有权重张量T’ \in \mathbb{R}^{3 \times d’ \times d}的注意力头,记为 \text{attn}(X_q, X_{kv}, T’),依赖于额外的位置编码 P_q \in \mathbb{R}^{d \times N_q}和 P_{kv} \in \mathbb{R}^{d \times N_{kv}}。它首先计算所谓的查询、键和值嵌入,在添加了查询和键的位置编码之后:

其中 T’ 是 T’_1、T’_2、T’_3 的拼接。注意力权重 \alpha 是通过查询和键之间的点积的软最大值计算的,使得查询序列的每个元素都能关注到所有键值序列的元素(i 是查询索引,j 是键值索引):

在本文中:

首先通过Transformer的Encoder,对图像特征作自注意力,再通过设计可学习的物体查询序列先进行自注意力,最后将图像特征作为KV,以物体查询序列去作查询,最终将结果通过前馈的FFN获得类别标签和框的位置信息
总结:
采用CNN网络作为图片特征提取器,利用Transformer将物体查询和图像特征进行融合,最后通过FFN获取物体类别标签和框的位置信息