目的:
采用SAM生成的2D掩膜,借助Nerf生成物体的3D掩膜
方法:
前置知识:
Nerf:
利用一个多视角的2D图像训练集I,学习一个函数f_\theta:(x, d) \rightarrow (c, \sigma),该函数将一个点的空间坐标x \in R ^3和视角方向d \in S^2映射到相对应的颜色c \in R^3和体积密度\sigma \in R上,此处的函数f通常由MLP来表示,参数为\theta
渲染一张图像I_\theta,需要将射线r(t) = x_0 + td从相机位置投射出去,这里的x_0是相机位置,d是射线方向,t是原点到点的距离,通过体渲染算法,可以获得射线r的RGB颜色I_\theta(r)
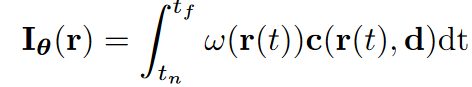
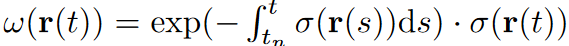
SAM:
接收图像I和提示P作为输入,输出相应的2D分割掩膜
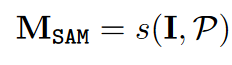
模型:
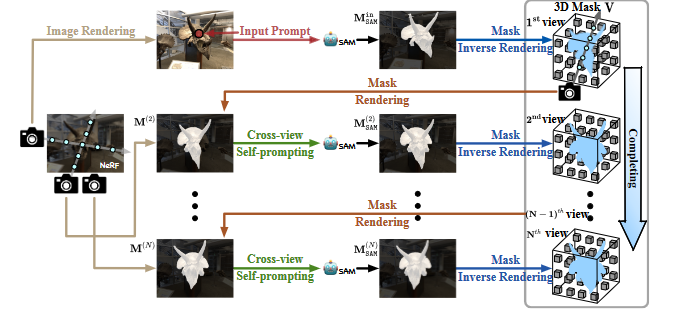
假设已经在图像数据集I上训练了一个Nerf模型
从特定视角生成的图片I_{in}由预训练的Nerf模型生成,然后将这张被渲染出来的图片和一组提示(本文中常用一组点)P_{in}输入到SAM模型中,获得对应的2D分割掩码M_{in}^{SAM},将掩码逆渲染投影到3D掩膜V\in R^3上
从3D掩膜渲染一个新视角的2D分割掩膜,然而,此时的掩膜通常是不准确的,本文采用了跨视角自提示方法从渲染的掩膜中提取点提示P,并将它们输入到SAM中,生成了更准确的2D掩膜,将生成的新视角的2D掩膜投影到体素网格上以完成3D掩膜,后续迭代执行,此处仅有3D掩膜的网络需要优化
逆渲染投影:
3D掩膜被表示为体素网格V \in R ^{L \times W \times H},其中每个顶点被初始化为0的软掩膜置信度分数
来自每个视角的2D掩膜的每个像素的渲染为:
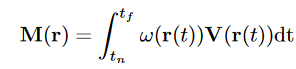
其中密度来自预训练的Nerf,V是体素网格中读取的置信度分数
逆渲染的目标是根据预训练的Nerf带来的密度增加V,这里的M_{SAM}为SAM模型生成的掩码,此外添加负的修正
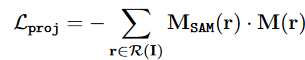
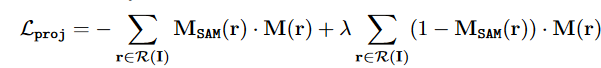
跨视角提示:
从每个视角手动选择并生成2D掩膜是耗时且不切实际的,因此设计了一套跨视角提示方法
目标是从渲染的2D掩膜中提取一组提示点P,帮助SAM生成尽可能准确的2D分割结果
懒得翻译了,自己看


总结:
1.利用预训练的nerf模型,为3D掩膜提供密度的先验
2.采用预训练的nerf渲染出的图片,通过提示点和SAM生成2D掩码,并指导3D掩膜的生成
3.利用3D掩膜投影出2D掩膜,并利用跨视角提示生成对应的提示点,经过SAM提高新视角渲染图的质量
4.迭代训练,最终优化3D掩膜的体素网络