目的:
零样本分割任务
方法:
大语言模型具有强大的零样本和少样本泛化能力,可以泛化到训练期间未见过的任务和数据分布
在计算机视觉中,问题可以被分为以下三个:
- 什么任务可以实现零样本泛化?
- 对应的模型架构是什么?
- 什么数据可以支持这个任务和模型?
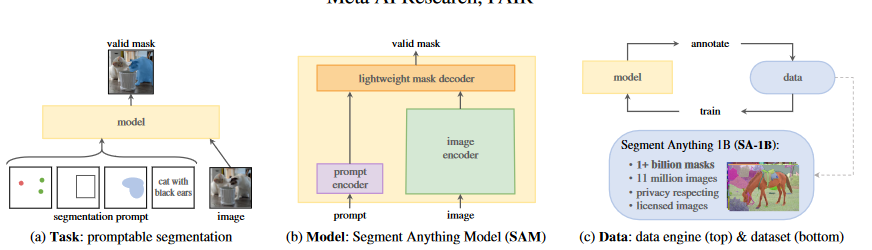
任务:
通过提示技术在新的数据集和任务上进行零样本和少样本学习,即通过分割提示返回一个有效的分割掩膜
将提示的概念从NLP转化为分割任务,分割任务的前提可以是一组前景,背景的电,大致的框,掩膜,自由形式的文本,或者任何提示信息,要求返回一个有效的分割掩膜
预训练:
为了在任意提示下都能返回一个有效的掩膜,设计为每个训练样本模拟一系列提示,并将模型的掩膜预测与GT对比,目标是为任何提示返回一个有效掩膜
零样本:
可以通过设计合适的提示来将预训练模型解决下游任务
模型:
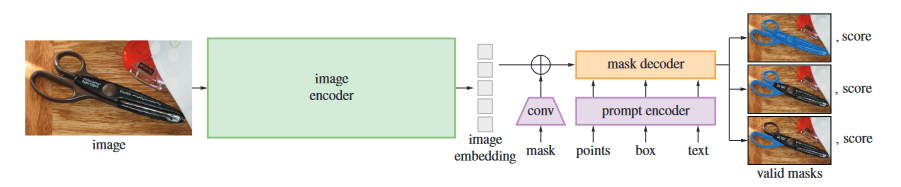
SAM由三个组件组成:图像编码器、灵活的提示编码器和快速的掩膜解码器
图像编码器:
采用MAE与训练的ViT,图像编码器对每张图像使用一次
具体细节见下

提示编码器:
考虑两种形式的提示:稀疏的点,框,文本和密集的掩膜,通过位置编码和每种提示嵌入的学习综合来表示点和框,通过CLIP的文本编码器来嵌入文本,通过卷积来嵌入密集提示的掩膜,与图像嵌入按元素求和
具体细节读论文


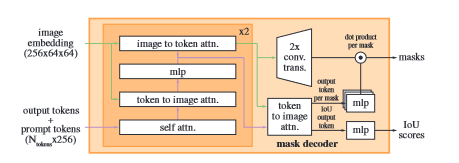
掩膜解码器:
通过变形的Transformer解码器,使用自注意力和交叉注意力更新所有嵌入,最后对图像嵌入进行上采样,用MLP映射到线性分类器
总结:
1.设计预训练模型,可以通过设计提示来适应不同的下游任务
2.该预训练模型的目的是无论什么提示输入,都返回一个合理的掩码表示
3.多提示采用不同的特征提取器,利用注意力进行特征融合