目的:
开集目标检测器 检测任意对象 支持类别名称或指代表达进行人机交互
方法:
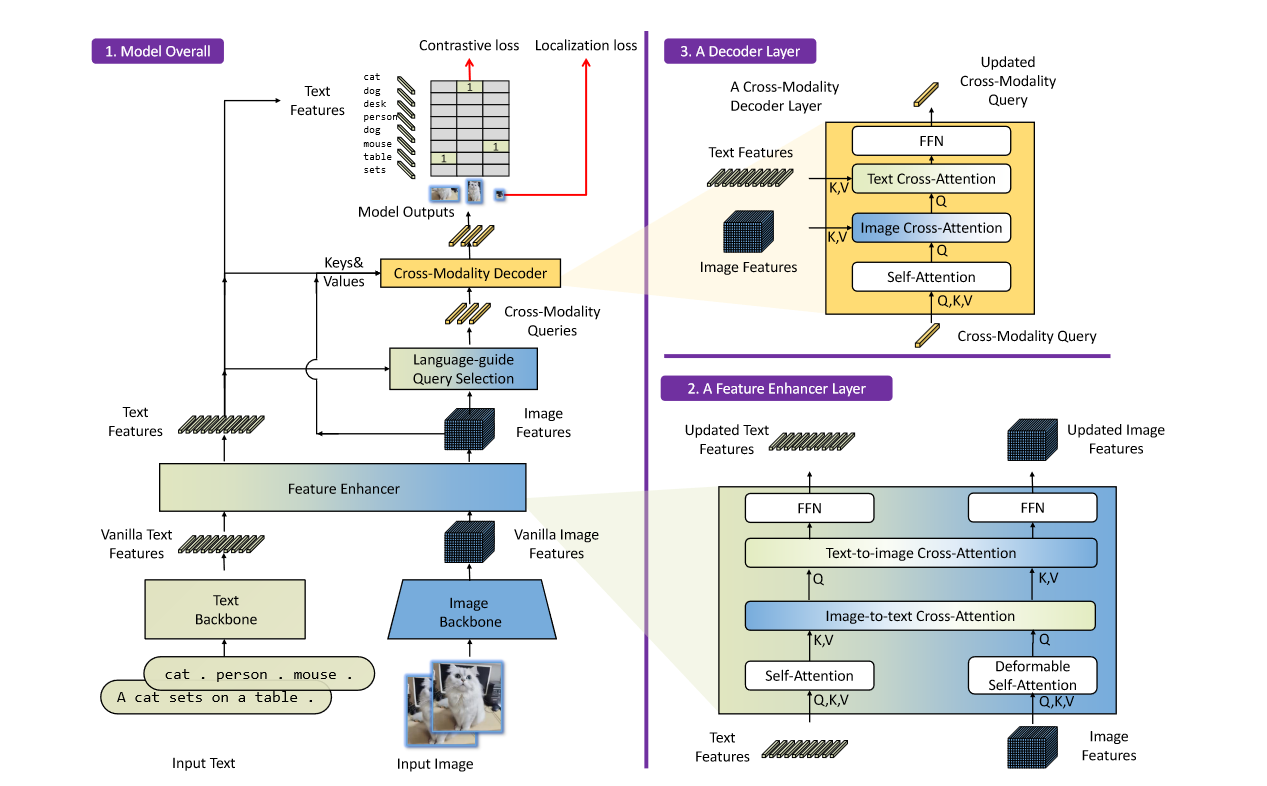
特征提取和融合:
对于图像,用Swin Transformer等骨干网络提取多尺度图像特征,使用Bert等网络提取文本特征
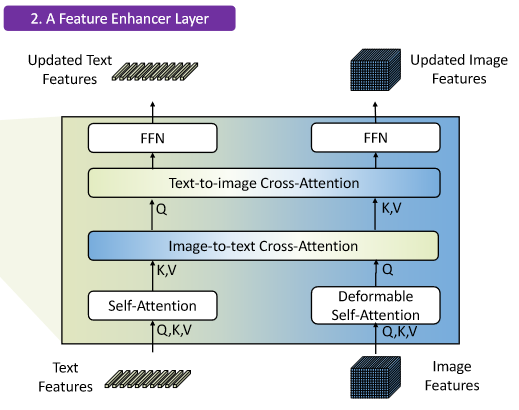
在提取了图像和文本特征后,输入到特征增强其进行跨模态的特征融合
特征融合部分,对图像特征和文本特征采用了自注意力,并且设计了文本到图像和图像到文本的交叉注意力机制
基于语言的查询选择:
利用输入文本来直到对象检测,选择与输入文本更相关的特征作为解码器的查询
# image_features: (bs, num_img_tokens, ndim)
# text_features: (bs, num_text_tokens, ndim)
# num_query: int
def language_guided_query_selection(image_features, text_features, num_query):
"""
基于语言的查询选择算法
参数:
image_features: 图像特征, 形状为 (bs, num_img_tokens, ndim)
text_features: 文本特征, 形状为 (bs, num_text_tokens, ndim)
num_query: 查询数量
返回:
topk_proposals_idx: 前K个查询的索引, 形状为 (bs, num_query)
"""
# 计算图像特征和文本特征之间的相关性得分
logits = torch.einsum("bic,btc->bit", image_features, text_features) # 形状为 (bs, num_img_tokens, num_text_tokens)
# 对每个图像特征取最大值以获取相关性得分
logits_per_image_feature = logits.max(dim=-1)[0] # 形状为 (bs, num_img_tokens)
# 选择得分最高的特征索引
topk_proposals_idx = torch.topk(logits_per_image_feature, num_query, dim=1)[1] # 形状为 (bs, num_query)
return topk_proposals_idx
选择K个得分最高的特征索引来初始化解码器查询,同样的,位置部分是动态锚框,内容查询在训练过程中是可学习的
跨模态解码器:
跨模态查询会通过一个自注意力层,一个与图像的交叉注意力层,一个与文本的交叉注意力层,最后通过FFN,与DINO相比,增加了一个文本的交叉注意力层
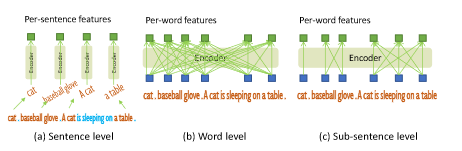
子句级文本特征:
文本提示可以用句子或者词语表示,句子回提取短语并丢弃其他词语,可以消除词语之间的影响,会丢失细粒度信息,后者可以一次前向传递多个类别名称,但是回引入不必要的依赖,本文采用了注意力掩码,消除了不同类别之间的影响,同时保留每个词的特征
损失函数设计:
与DINO类似,设计预测和真实值之间的二分匹配
总结:
1.添加文本特征,并且在提取特征时将文本特征和图像特征融合
2.用相关度高的融合特征来指导查询,并且后续与文本图像执行交叉注意力,充分将文本信息融入进去
3.设计注意力掩码,保留每个词特征的同时消除不同类别之间的影响